MIT 6.S081 - Lab System calls - overview
实验二前提条件:
- xv6 book chapter 2,chapter 4:4.3 & 4.4(看不懂就算了,之后也会看)
- 课程 lec03:Lec03 OS Organization and System Calls (Frans) - MIT6.S081 (gitbook.io)
- 部分 xv6 源码
主题:
完成两个系统调用:trace 和 sysinfo。
起始
这次实验更多的是概念上的理解,实际的实验内容和细节没有实验一多;但是概念确实有点多,上手没有实验一快。
怎么做:
xv6 book、课程翻译、xv6 源码、学校的指导书、网上的 GDB 调试知识,轮番着反复看。知识了解到一定程度就可以去写实验了,不必了解的过于透彻;在写实验的时候进一步接触源码,照葫芦画瓢的写完之后必然有新的发现和问题,这个时候再带着问题去读之前没看懂的资料。
这次学校的指导书意外的帮到我完成实验了,没有指导书的话,我可能在了解到众多知识之后像个没头苍蝇一样不知道从何处下手完成实验。同时报告中的问题也是在有意的指导你去看关键的、有用的部分。
PLUS:写完之后返回来看,GDB 调试在这次实验中不是必须的。
结束:报告
一 回答问题
1 阅读 kernel/syscall.c,试解释函数 syscall() 如何根据系统调用号调用对应的系统调用处理函数(例如 sys_fork)?syscall() 将具体系统调用的返回值存放在哪里?
在编译系统后,user/usys.pl 生成了汇编 user/usys.S,这其中的代码会被链接到将要运行的程序中去,我们可以通过查看程序的反汇编 asm 得知,例如:in user/sysinfotest.asm
00000000000005ae <fork>:
# generated by usys.pl - do not edit
#include "kernel/syscall.h"
.global fork
fork:
li a7, SYS_fork
5ae: 4885 li a7,1
ecall
5b0: 00000073 ecall
ret
5b4: 8082 ret系统调用号总是被存在寄存器 a7 中。
而在 kernel/syscall.c 中,函数 syscall() 调用系统调用函数,以及存放返回值的方法是:
p->trapframe->a0 = syscalls[num]();num 为系统调用号。syscalls[num]() 来自:
extern uint64 sys_chdir(void);
extern uint64 sys_close(void);
extern uint64 sys_dup(void);
...(more)
extern uint64 sys_uptime(void);
extern uint64 sys_trace(void);
extern uint64 sys_sysinfo(void);
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork,
[SYS_exit] sys_exit,
[SYS_wait] sys_wait,
...(more)
[SYS_close] sys_close,
[SYS_trace] sys_trace,
[SYS_sysinfo] sys_sysinfo,
};这些函数来自于 kernel/syscall.c 包含的头文件,即 kernel 中其他文件中写着这些函数的真正实现。
返回值存放在寄存器 a0 处。
2 阅读 kernel/syscall.c,哪些函数用于传递系统调用参数?试解释 argraw() 函数的含义。
所有的 sys 系统调用的参数都是 void。参数的获取采用了另一种方式。
kernel/sysproc.c:sys_sleep(void) 为例:
uint64
sys_sleep(void)
{
int n;
uint ticks0;
if (argint(0, &n) < 0)
return -1;
acquire(&tickslock);
ticks0 = ticks;
while (ticks - ticks0 < n)
{
if (myproc()->killed)
{
release(&tickslock);
return -1;
}
sleep(&ticks, &tickslock);
}
release(&tickslock);
return 0;
}函数内部使用 int argint(int n, int *ip) 获取参数,argint 来自于 kernel/syscall.c。
类似的函数还有:
int argaddr(int n, uint64 *ip)int argstr(int n, char *buf, int max)
他们都直接或者间接的调用了 static uint64 argraw(int n)。
static uint64
argraw(int n)
{
struct proc *p = myproc();
switch (n)
{
case 0:
return p->trapframe->a0;
case 1:
return p->trapframe->a1;
case 2:
return p->trapframe->a2;
case 3:
return p->trapframe->a3;
case 4:
return p->trapframe->a4;
case 5:
return p->trapframe->a5;
}
panic("argraw");
return -1;
}可以看到参数就是从进程的 trapframe 的寄存器上取下来的,看起来只支持 a0 - a5。也就是说在函数调用号存在 a7 的时候,系统调用需要的参数也存在这些个寄存器里了。
另外,获取参数的函数不止 kernel/syscall.c 中这几个。
例如:kernel/sysfile.c:argfd(),通过参数文件描述符 fd 获得 file。
3 阅读 kernel/proc.c 和 proc.h,进程控制块存储在哪个数组中?进程控制块中哪个成员指示了进程的状态?一共有哪些状态?
进程控制块存储在 proc[NPROC] 数组中。
进程控制块中 enum procstate state 成员指示了进程的状态。
一共有五个状态。
enum procstate
{
UNUSED,
SLEEPING,
RUNNABLE,
RUNNING,
ZOMBIE
};4 阅读 kernel/kalloc.c,哪个结构体中的哪个成员可以指示空闲的内存页?xv6 中的一个页有多少字节?
kmem 的 freelist 成员可以指示空闲的内存页。
struct run
{
struct run *next;
};
struct
{
struct spinlock lock;
struct run *freelist;
} kmem;由 kernel/riscv.h 可知,xv6 中的一个页有 4096 字节。
#define PGSIZE 4096 // bytes per page5 阅读 kernel/vm.c,试解释 copyout() 函数各个参数的含义。
kernel/vm.c/copyout
// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
int copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)使用 copyout 的例子:fstat(fd, &st),sys_fstat 调用了 filestat。
kernel/file.c:filestat()
// Get metadata about file f.
// addr is a user virtual address, pointing to a struct stat.
int
filestat(struct file *f, uint64 addr)
{
struct proc *p = myproc();
struct stat st;
if(f->type == FD_INODE || f->type == FD_DEVICE){
ilock(f->ip);
stati(f->ip, &st);
iunlock(f->ip);
if(copyout(p->pagetable, addr, (char *)&st, sizeof(st)) < 0)
return -1;
return 0;
}
return -1;
}p->pagetable 就是当前进程的页表,addr 就是用户传进来的 st 的虚拟地址,即 user virtual address;
(char *)&st, sizeof(st)) 指的就是这个函数刚刚创建的 st 和它的长度。
在 copyout 的时候,我们不可能对 user virtual address 直接进行什么操作,因为这个地址不是内核中的地址。所以不会出现什么:
stati(f->ip, addr);别把 user 的 st 的 addr 和 kernel 的 st 的 &st 搞混了。
二 实验详细设计
感觉我能说的都被指导书说了。

1 trace 参数掩码逻辑
sys_trace 的作用只是给 proc 打个标记 mask,要对之后进行的系统调用进行追踪,需要在 kernel/syscall.c:syscall() 这个进行系统调用的地方来打印信息。哪些系统调用是我们在追踪的,哪些不是的,是使用 mask 来区分的。
开始的时候我就算看了指导书,也没能理解 mask 参数的设计,还想着 mask 如果就是系统调用号就很方便了。
好好的 trace(SYS_fork),怎么就写成 trace(1 << SYS_fork) 了呢?
if ((1 << num) & (p->mask))
{
printf("%d: sys_%s(%d) -> %d\n", p->pid, syscallNames[num], arg0, p->trapframe->a0);
// PID: sys_$name(arg0) -> return_value
}经人指点之后明白了道理。
如果传入的参数是系统调用号的话,就只能追踪一个调用,不能同时追踪多个。
使用 1 << SYS_${name},判断条件为:(1 << num) & (p->mask),就可以做到。例如:
- 设参数 mask = 11111;
- 那么我追踪了 00001、00010、00100、01000、10000(11111 与之按位与的结果都为 “1”)
- 即(00001 没有对应)、1 << 1、1 << 2、1 << 3、1 << 4;
- 也就是 fork、exit、wait、pipe。
所以 mask 的一位就对应一个系统调用。
xv6 框架给的系统调用一共有 21 个,mask 设置为更大一点的 0xffff_ffff,应该就可以追踪所有的系统调用。
最后,我问同学为啥知道不看指导书就知道这个是常见的掩码设计,他说他经常看到这样的设计(呜呜)。然后去查了一下,mask 这个单词就是掩码的意思,难绷。
2 PCB 结构体和 fork()
第一章了解到 fork() 复制进程,复制了但没完全复制。今天就来这个说法什么意思。
kernel/proc.c:fork()
// Create a new process, copying the parent.
// Sets up child kernel stack to return as if from fork() system call.
int fork(void)
{
int i, pid;
struct proc *np;
struct proc *p = myproc();
// Allocate process.
if ((np = allocproc()) == 0)
{
return -1;
}
// Copy user memory from parent to child.
if (uvmcopy(p->pagetable, np->pagetable, p->sz) < 0)
{
freeproc(np);
release(&np->lock);
return -1;
}
np->sz = p->sz;
np->parent = p;
// copy saved user registers.
*(np->trapframe) = *(p->trapframe);
// Cause fork to return 0 in the child.
np->trapframe->a0 = 0;
// mask
np->mask = p->mask;
// increment reference counts on open file descriptors.
for (i = 0; i < NOFILE; i++)
if (p->ofile[i])
np->ofile[i] = filedup(p->ofile[i]);
np->cwd = idup(p->cwd);
safestrcpy(np->name, p->name, sizeof(p->name));
pid = np->pid;
np->state = RUNNABLE;
release(&np->lock);
return pid;
}先 Allocate process,然后复制 pagetable,size 也复制,复制 trapframe(user registers),打开的文件表 ofile,当前目录 cwd...
不同的地方:np 的 parent 指向当前 proc;np->trapframe->a0,也就是子进程 fork() 返回值设置为 0;而 fork() 的返回值,也就是当前进程 fork() 的返回值为 np->pid,也就是子进程的 pid。
看 fork() 的系统调用实现就可以很清楚的知道 fork 到底做了些什么事情,对复制的了解也更深了。
3 记录
学校的仓库里的改动为:
trace打印追踪信息的格式不同kernel/sysinfo.h:sysinfo成员增加了freefd- 对
nproc的定义不同(nproc,number of proc,到底是 - 显然评测脚本也改过了
学校仓库实验步骤:
Makefile添加user/user.h中添加系统调用接口(还有补充一个 struct sysinfo)user/usys.pl添加kernel/syscall.h添加系统调用号kernel/proc.h:proc 结构体定义添加 maskkernel/proc.c:fork()代码中添加 mask 的复制kernel/syscall.c添加 extern 声明和(*syscalls[])(void),修改syscall(),添加打印追踪的代码kernel/sysproc.c中添加sys_trace系统调用kernel/sysproc.c中添加sys_sysinfo系统调用(补充 #include)kernel/kalloc.c中添加freemem()kernel/proc.c中添加nproc()、freefd()kernel/def.h中补充freemem()、nproc()、freefd()函数定义
最后改动的文件:
xv6-labs-2020
├── Makefile
├── kernel
│ ├── kalloc.c
│ ├── proc.c
│ ├── proc.h
│ ├── sysproc.c
│ ├── syscall.c
│ ├── syscall.h
│ └── def.h
├── user
│ ├── user.h
| └── usys.pl
└── time.txt4 freemem()
不一定真的很懂,照着 kernel/kalloc.c 其他函数写就行。
uint64
freemem(void)
{
uint64 i = 0;
struct run *r;
r = kmem.freelist; // 接上 kmem 的 freelist
while (r)
{
// 如果不为空,那么就是还有空间
i++; // 也就是有一个 1 * 4096 bytes 的空间
r = r->next; // 向后继续找
}
// PGSIZE is in riscv.h, 4096 bytes
return i * PGSIZE;
}5 nproc()、freefd()
nproc()
uint64
nproc(void)
{
uint64 n = 0;
struct proc *p;
for (p = proc; p < &proc[NPROC]; p++)
{
// MIT 版本
if (p->state != UNUSED)
n++;
// // HITSZ 版本
// if (p->state == UNUSED) n++;
}
return n;
}freefd()
uint64
freefd(void)
{
uint64 free = 0;
struct proc *p = myproc();
for (int fd = 0; fd < NOFILE; fd++)
{
// 有了就跳过
if (p->ofile[fd])
continue;
// 如果该下标没有对应 file 指针,那就是可用的
free++;
}
return free;
}6 sys_sysinfo
sysinfo 的难度全在这里了。
- 指针是 64 位的,所以可以用
uint64定义; - 注意使用
copyout
uint64
sys_sysinfo(void)
{
// 现在 addr 是得来的用户的虚拟地址
uint64 addr = 0;
if (argaddr(0, &addr) < 0)
return -1;
struct sysinfo info;
info.freemem = freemem(); // kernel/kalloc.c
info.nproc = nproc(); // kernel/proc.c
info.freefd = freefd(); // kernel/proc.c
// 需要 copyout
struct proc *p = myproc();
if (copyout(p->pagetable, addr, (char *)&info, sizeof(info)) < 0)
return -1;
return 0;
}7 另外的感想
sysproc.c 和 sysfile.c 虽然说是真正的系统调用,可是看完之后觉得还是只是一个接口,多半在处理由 kernel/syscall.c 分离的参数,然后调用 kernel 里其他文件的函数。下面举两个 sysproc.c 里的典型例子:
uint64
sys_exit(void)
{
int n;
if (argint(0, &n) < 0)
return -1;
exit(n);
return 0; // not reached
}
uint64
sys_kill(void)
{
int pid;
if (argint(0, &pid) < 0)
return -1;
return kill(pid);
}虽然这次实验没有过多的涉及 sysfile.c,但是其开头的注释就写了:
File-system system calls.
Mostly argument checking, since we don't trust user code, and calls into file.c and fs.c.
大多数只是参数检查(不相信用户输入),实际的调用会进入 file.c 和 fs.c。
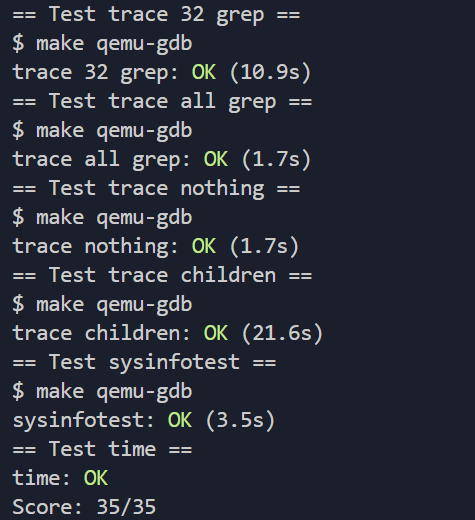
三 实验结果截图