MIT 6.S081 - Lab Lock - Buffer cache (1) 分析原始设计
Cache 结构
CPU - Disk 中的缓存,使用 DRAM 的一部分作为其物理载体。
阅读 kernel/bio.c 发现,该缓存的工作方式是只缓存读,而没有缓存写。
即上层文件系统调用 bread(),内部调用 bget() 并检查 valid,如果为 0 即未命中,然后去磁盘读取 virtio_disk_rw(b, 0);上层文件系统调用 bwrite(),内部(几乎是直接)直接调用 virtio_disk_rw(b, 1)。
之前学过的 CPU - DRAM 的 Cache 是缓存读也缓存写的。
Cache 数据结构以及使用
赏析一下这个双向循环链表的设计。
学过的数据结构的知识狠狠的用上!难得有如此实际的场景,我们就来一部分一部分解读吧。
kernel/bio.c:binit()
首先是一个熟悉的双向循环链表的头节点初始化。
// init
(bcache.head).prev = &bcache.head;
(bcache.head).next = &bcache.head;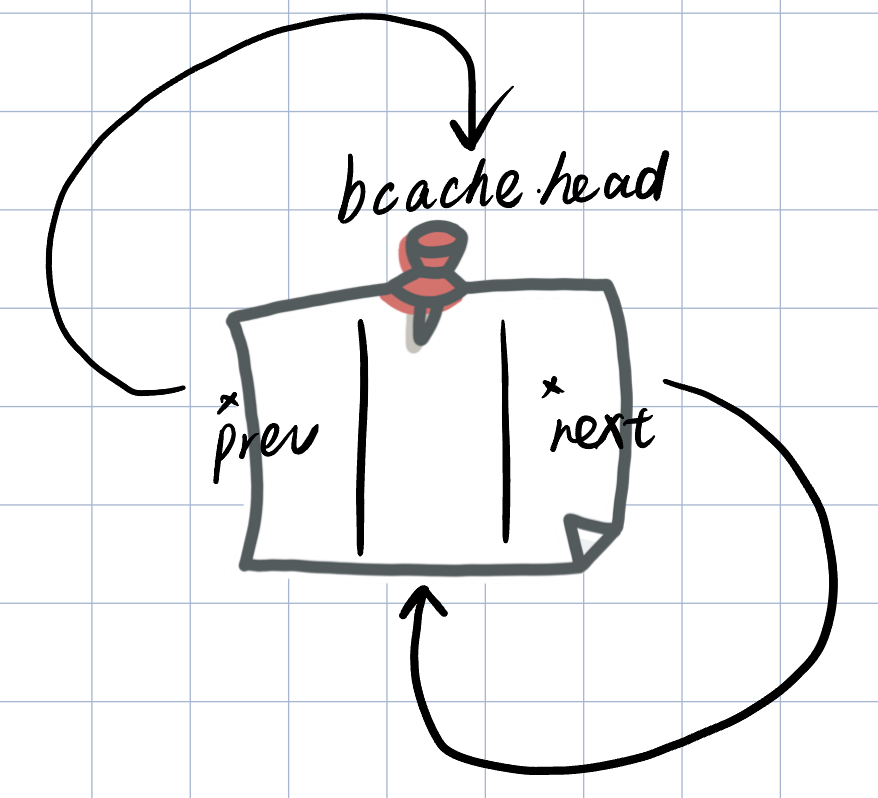
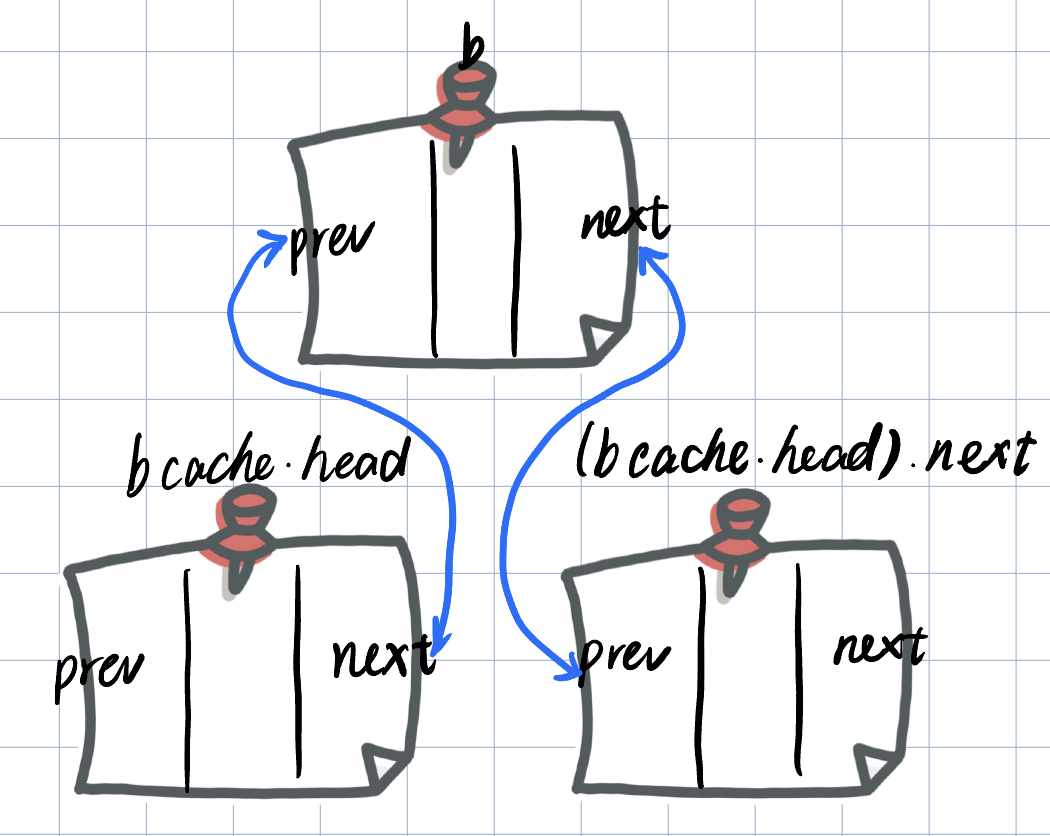
之后进行了把数组的元素全部插入链表上的操作,插入的方法是头插法。
for (b = bcache.buf; b < bcache.buf + NBUF; b++)
{
// add b between bcache.head and bcache.head.next
b->next = (bcache.head).next;
b->prev = &bcache.head;
initsleeplock(&b->lock, "buffer");
(bcache.head.next)->prev = b;
(bcache.head).next = b;
}一共需要修改四处(最后修改 (bcache.head).next,不然链表后面的元素就失踪了)。
kernel/bio.c:bget()
在数据结构方面,我们需要注意的地方就是 for 循环的开头的部分:
// Is the block already cached?
// from bcache.head.next to bcache.head
for (b = (bcache.head).next; b != &bcache.head; b = b->next)// Not cached.
// **Recycle** the least recently used (LRU) unused buffer.
// diff from the former
for (b = (bcache.head).prev; b != &bcache.head; b = b->prev)前一个是从 (bcache.head).next 开始(也就是 most recent used 端),到 bcache.head 结束,用 b = b->next 转移到下一个元素;
后一个是从 (bcache.head).prev 开始(也就是 least recently used 端),到 bcache.head 结束,用 b = b->prev 转移到上一个元素。
kernel/bio.c:brelse()
if (b->refcnt == 0)
{
// no one is waiting for it.
// remove b between b->next and b->prev
(b->next)->prev = b->prev;
(b->prev)->next = b->next;
// deal with b itself
// add b between bcache.head and bcache.head.next
b->next = (bcache.head).next;
b->prev = &bcache.head;
(bcache.head.next)->prev = b;
(bcache.head).next = b;
}refcnt = 0 的缓存块,我们先将其从表中取出,然后移动到 head.next 处(most recent used 端)。
头插之前画过了,那画个取出 buf b 的图好了。
为什么要用链表
原本的设计用的是双向循环链表。我们知道各种链表比较下,双向循环链表的查找性能,或者说实现 LRU 算法的性能最好。
其实还有个问题:为什么要用链表呢?就单纯使用数组不行吗?不也可以实现 LRU 算法吗?——比如在 bget 查找 LRU 的时候,只要访问数组的开头或者末尾就可以了。
好吧不卖关子了。问题其实并不出在 bget 上——你只比较 bget 的话其实两者区别不大,因为查找性能都很优秀。实际的问题出在 brelse 上。
上层文件系统调用 brelse 释放了不用的缓存块,这个时候先把 refcnt - 1,然后检查 refcnt,如果为 0,那么就是不再访问的缓存块。将其从表中取出并移动到 head.next (most recent used 端)处。
整个 NBUF 长度的链表就是被 brelse 这个行为驱动起来的。我们也可以发现 kernel/fs.c(也就是上层文件系统)频繁的调用它,那么你可以想象这个链表就在很快的变动着。
每当一个内核线程使用完一个缓存块后,应该对那个缓存块调用 brelse。
我们想一下 “从表中取出,移动到 most recent used 端” 的这个操作,也就是对表的插入和删除操作。很明显数组(或者说顺序表)在这方面的性能是不如链表的。
关于优化
只有一把自旋锁 bcache.lock 用于保护整个 bcache,这么粗粒度的处理是不好的。需要减小锁粒度。
指导书给出了两种优化方案:(可以两个方案一起使用,也可以单独分开用)
- 使用 哈希表 ,将各块块号
blockno的某种散列值作为 key 对块进行分组,并为每个哈希桶分配一个专用的锁。通过哈希桶来代替链表,当要获取和释放缓存块时,只需要对某个哈希桶进行加锁,桶之间的操作就可以并行进行,提供并行性能。 - 移除空闲缓存块列表(
bcache.head)。使用 时间戳 作为判断缓存块最一次被访问的顺序的依据。
之后的文章将会去实现这两个优化方案。